
During my recovery from shoulder surgery I read through Felienne Herman's The Programmer's Brain. I have mostly good things to say about it, although there are also a number of issues with the early parts of the book that are, shall we say, stuck in a mindset with which I disagree.
So let's talk about the later parts first.
The good parts
The Programmer's Brain is a book about the tasks that programmers typically do, and what a variety of disciplines tell us can make doing those tasks easier, better, more effective and even more pleasurable. She doesn't worry too much about "Flow" but she does go into a lot of detail about the classic costs of interrupting a programmer. So she covers a lot of ground.
One of the things she recommends-- in fact, this is a recommendation I've seen a lot from people who study things like "What makes a 10X programmer"-- is simple: read a lot of source code. And she has a section on how to read source code that starts with: find a focal point. Find a place in the code that interests you most by just scanning the text, understand what the code at that focal point does, and spread your understanding out from that center, slowly documenting how it relates to others. She also recommends you create a new branch (if you use Git-- and who doesn't these days) and annotating the code itself, using a custom tag such as your usual username (like "elfsternberg") and letting your IDE re-find those annotations, to help you understand the code better. In fact, if it helps, feel free to refactor the code to your heart's desire, placing related code nearby according to your ideal scheme, rather than the original developer's.
A few words are spent on applying classic learning techniques to code, such as highlighting the important parts, drawing diagrams of connected knowledge, asking what you expect a given subset of code to do and then affirming that through examination, and summarizing what you discovered. She also goes into making-- and collecting-- mental models of how code works through this reading process, so that you can apply them, transfer those models, to other code. Since code does something, our mental models are often "notational machines," abstract ideas about how something works. My understanding of how CPUs work hasn't evolved much since my 680x0 assembly language days, but until I start writing system code that cares about the local cache (which seems likely in the coming year or so) that model is actually strong enough for writing Rust applications.
Part 3 of the book was the most useful. There's an excellent section on naming-- and advice on naming after you've written the code. Her rationale goes something like this: you're too busy thinking about the machine to give good names. Give workable names, then go back and rename according to a naming template your team has agreed upon. Naming schemes should be consistent across the codebase, and names should be domain-driven wherever possible. Names should also be whole words, not abbreviations-- but the more syllables in a name, the harder they are to recall, so keep that in mind. There's a reason one of the few "programming" posters I have on my walls is The Seven Stages of Naming.
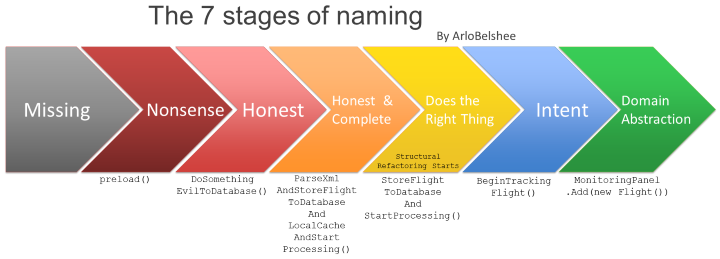
The next section is on code
smells and how they make
understanding code more difficult; the worst examples are those that prevent the
programmer from "chunking" understanding, from saying "Oh, this block does X,
and this block does Y." And the worst offenders are names that do something
other than what convention suggests-- a function whose name is the opposite of
what it does, or a non-boolean variable that starts with is_. She has an
excellent chapter describing "automization," where you can go from a base
understanding of a semantic action in code to an internalized understanding, and
how to accelerate the process. I'll be using that one a lot.
One thing that I really liked in this section was the section on "germane load." That's the free mental space you need to take what you've done and turn it into learning. If you're using 100% of your brain to solve a new problem, you don't have enough mental bandwidth to take your solution and generalize it, turn it into knowledge, and use it again the next time. You have to take time and space during and after this to do just that: write down what you've understood.
Programming, she writes, is "Searching through code, comprehending it what it does, taking your understanding and writing new code, taking your understanding and extending existing code, and exploring possible solutions to a greenfield problem." When you're working on a problem and you're interrupted, knowing which one of these you're doing is vital to saving your state (if you have the time to save your state) by writing down your mental models and your current list of local goals toward completing the assignment before dealing with the interruption.
Finally, she talks about the dimensionality of the development experience, which segues nicely into my recent reading of Codebases as Communication. Code, she writes, has the following metrics: Error proneness (the language many, or few, qualities that prevent error); consistency (the project is written in a consistent way, so you don't need to learn different idioms to understand different parts); diffuseness (the code is, or is not, written so that each conceptual unit fits on a single screen, allowing comprehension); visibility (the code or language has no hidden tricks you "just have to know" to understand a given chunk of code); provisionality (the tools you use can-- or cannot-- help you think while you work); viscosity (the code base is, or is not, very hard to change in one locale without a cascade of changes being needed, making it hard to change); progressive (the language allows you to experiment with variations on your solution without penalizing you with long delays); expressiveness (the language itself is consistent in how its semantics and syntax align, with few "special cases" you have to waste brain cycles on); closeness (the language aligns well with the domain in which you're working); notational (the code allows for long variable and function names, as well as comments, allowing the programmer to add information to the codebase for future readers); abstracted (the code uses appropriate abstraction to separate different levels of application); visible (the code makes it easy to see what parts do what).
She has a lovely matrix of how the dimensions affect the five different tasks of programming, but you'll have to buy the book to see it.
Her last chapter is a very good one on "onboarding," especially helping new developers understand your codebase. I am having this problem right now as our team grows; we have a multi-tiered engine in which "the domain of insurance application forms" is isolated into a large but distinct code base, and then two tiers that turn that into "a form manager for HTML," and then we have the actual rendering library, which itself is isolated into "a collection of form components," "a wizard for pages of the form," and specific "decorations for components based on the ID of an element of the insurance application form." Trying to get the juniors to see these different responsibilities for what they are has been hard. They keep wanting to put specific element IDs into the input objects, and that's not the right solution; the right solution is to recognize that a specific kind of input is missing, add it, then add the connection between the two to the dispatch table.
The roadblocks
All right, so that's the "good parts." For me, though, there were roadblocks. The first roadblock, and maybe this is on me, is in the section on "understanding code." Programmers are puzzle-solvers first and foremost, and experienced programmers have a toolbox of heuristics for solving them. Take this example from her book:
1 LET N2 = ABS (INT (N))
2 LET B$ = ""
3 FOR N1 = N2 TO 0 STEP 0
4 LET N2 = INT (N1 / 2)
5 LET B$ = STR$ (N1 - N2 * 2) + B$
6 LET N1 = N2
7 NEXT N1
8 PRINT B$
9 RETURN
She says that, of her three examples, this is "the hardest to read" because it
involves such specific code that it's not obvious what it does. My brain went:
"For loop-- iteration. Longest line-- hmm-- okay, that math, ah above! it's
integer division, so the result is 0 or 1, so... wait, is this conversion
to binary? It is!" ... and that thought took less than two seconds.
But that's a quibble. I'm an expert, after all. There are other aspects.
One that bothered me the most is her suggestion that beginning programmers
re-write functional code into imperative code. She writes that it might be
easier to replace lambdas, list comprehensions, map/reduce/filter, and if
expressions, with named functions, for-loop equivalents, and if
statements-- which might be true, if that's all the developer knows. But she
fails to tell the developer, "learn these shorter methods-- they're less
error-prone and ultimately easier to read." Which is even more true.
There were two sections that made me a bit upset, though. The first was in the "roles of variables." She says that almost all variables are in one of several roles, and knowing what role they're playing can be useful. Those roles are: constant, stepper, flag, walker, most recent, most wanted, accumulator, container, follower (previous value), organizers, and temporaries.
I'm upset at this for two reasons: first, an "organizer" is described as "a data structure that reorganizes another data structure to make it more accessible-- such as converting a string to an array of code points." Which makes it a container with some semantics. Putting on my Design Patterns hat, an organizer is a facade in front of an existing data structure. Knowing this may be useful, but unless you take the extra step of understanding that it's a facade providing extra semantics, you're not getting anywhere.
Secondly, too many of these roles are... error-prone. "Flag," "Stepper," and "Walker" are code smells in their own right, and you shouldn't be using them. A flag exposes a missing feature; a stepper should be made extraneous with map/reduce/filter, and since a walker is just a stepper with extra powers it, too, should be replaced with map/reduce/filter.
In fact, that's one of my biggest complaints with the whole spate of programming "wisdom" these days. It treats recursion and the powers of recursion as something Reserved To The Gods, rather than what recursion really is: "You take a thing out of the problem set, process it, and put it into the accumulator. You now have a smaller problem set, so call the function again with the smaller problem set until it's empty." How hard is that? (Also, note: in a functional paradigm, 'most wanted' is a subtype of 'accumulator!') Switching to a functional style, even in a multi-paradigmatic language like Javascript or Python, eliminates half her "variable roles."
The other less-than-delightful section was simply this: "Some frameworks and techniques, like dependency injection, can fragment focal points so they are far apart and hard to link together."
I will not debate that many larger frameworks (cough NextJS cough) have a lot of "spooky action at a distance" moments, but singling out dependency injection as a diffusion code-smell is unwarranted; the whole point of dependency injection is based on the idea that your code should be written to an abstract interface and not some concrete implementation way the hell over there. If you write the interface well enough, it should be clear what the which is dependent upon the injected interface does without having to have a specific implementation of it in mind!
One thing that I would really love for this book to address is the cognitive advantages to certain API techniques. Felienne addresses some of this in her section on function signatures, and how having too many variables in the function signature is itself a cognitive burden, but she doesn't address how Narrow Waist Design can reduce both the number of functions an API needs, and the number of arguments any function in that API must take.
I am especially fond of narrow-waist architectures in which the payload to any API is devolved, piece by piece, into either requests for information or commands for mutation, without the facade of the API having to "know" too much about the payload itself (other than type-correctness, of course). That's a strategy I've learned for simplifying the development process; figure out where your borders are between interactive components, and then simplify, simplify, simplify.
Because it takes a lot of work to Make Simple Easy.
Conclusion
I don't want to be too harsh on this book. It's actually an awesome book, and as a technical lead I found its sections on organizing your code to be readable, understanding how junior developers will read your code, and understanding how to make your code coherent is incredibly valuable. As a developer with 30 years of experience, though, I found parts of it either out-of-date or out-of-touch with some modern development techniques that have evolved to deal with the unreadability of imperative code, the error-prone nature of mutable code, and the exposed machinery of iteration.
It's a worthwhile book, those quibbles aside, and I recommend it.